Rails7.1からcolumn,enum名に使えない名前が増える可能性が高いので注意
3行まとめ
- Rails 7.1 から
dup,freeze,hash,object_id,class,clone,frozenは column 名や enum の種類として使えなくなる可能性が高い - 該当 column を持つ Model の initialize で
ActiveRecord::DangerousAttributeErrorが発生する - 各位そういった名前を使わない、rename するなど身構えておきましょう
起きていた問題
会社の Rails アプリケーションに対して rails/rails の main branch を使ってテストを走らせていたら以下のようなエラーを数多く見かけるようになった。
ActiveRecord::DangerousAttributeError: object_id is defined by Active Record. Check to make sure that you don't have an attribute or method with the same name. # /usr/local/bundle/gems/factory_bot-6.2.1/lib/factory_bot/decorator/new_constructor.rb:9:in `new' # /usr/local/bundle/gems/factory_bot-6.2.1/lib/factory_bot/decorator.rb:16:in `send' ...
どうやらテストの前準備のレコード作成でコケている様子。(具体的には factory_bot の create(:xxxx))
object_id...?なんのことだ...?と思って調べてたら作成対象の model の association に object_id という column を持つ model が存在することが分かった。 ActiveRecord によって object_id メソッドを上書きされるの危険そうだなと思いつつ、なぜ Rails 7.0 ではエラーにならず Rails 7.1 で問題になるのか分からなかったので調べてみて原因を特定した。
変更が入ったのは上記 PR。column 名に hash という名前を使うと ActiveRecord が Object#hash をオーバーライドしてしまい、問題が発生していた。
その問題と今後発生しそうな問題を防ぐために Object クラスでオーバーライドされると困りやすい dup, freeze, hash, object_id, class, clone を AR が定義しようとするとエラーにする変更を加えたとのこと。
後続の変更で frozen? も使えなくなっている。AR は boolean の column に対しては自動的に ? 付きのメソッドを定義するので boolean の frozen column も使えなくなってそう。
これは column だけではなく enum によるメソッド定義でも同様なので enum の種類に frozen を使っているアプリケーションも書き換えが必要になるんじゃないかな。
まだ Rails 7.1 はリリースされていないので確定ではないものの、主張としては真っ当なのでそのまま入りそうな気がしている。 上記に該当するアプリケーションをお持ちの方は身構えておくと良いのではないでしょうか。
感想
git bisect コマンド初めて使ったんですが、これ便利ですね...
Rails の has many through 経由でモデルを削除すると destroy callback が呼び出されない
has many through の挙動についてずっと勘違いしていたところがあったので忘れないように書き留めておきます。
3行まとめ
- has many through のデフォルトの挙動では削除時に delete_all を実行したのと同じ挙動になり、callback が発火しない
- has many through のオプションに
dependent: :destroyをつけると destroy callback が呼び出され一般的に期待する挙動になる - has many through を使う際は常に
dependent: :destroyをつけるようにした方が良いのでは?
起きていた問題
例えば、図書館のような誰がどの本を借りているかを管理するアプリケーションがあったとすると、以下のような model が存在しているはず。
# == Schema Information # # Table name: users # # id :bigint not null, primary key # created_at :datetime not null # updated_at :datetime not null # class User < ApplicationRecord has_many :bookings has_many :books, through: :bookings end # == Schema Information # # Table name: books # # id :bigint not null, primary key # content :text # created_at :datetime not null # updated_at :datetime not null # class Book < ApplicationRecord end # == Schema Information # # Table name: bookings # # id :bigint not null, primary key # user_id :bigint not null # book_id :bigint not null # created_at :datetime not null # updated_at :datetime not null # class Booking < ApplicationRecord belongs_to :user belongs_to :book end
user_id: 1 のユーザーが借りている本を取得したい場合は以下のように記述できる。
User.find(1).books # => [<Book>, <Book>, ...]
また、user_id: 1 のユーザーが新たに book_id: 100 の本を借りる場合は以下のように記述できる。
このとき、Booking model に after_create callback が定義されていれば該当 callback が発火し、期待する処理を行うことができる。
User.find(1).books << Books.find(100) # Booking Create (xxx ms) INSERT INTO `bookings` (`user_id`, `book_id`) VALUES (1, 100)
また、user_id: 1 のユーザーが借りている本を全て返したい場合は以下のように記述できる。
このとき、Booking model に after_destroy や after_commit on: :destroy callback が定義されていても該当 callback は発火せず、期待する処理は行われない。
ログには Delete All と表示されているのでどうやら delete_all を実行したときと同じような挙動になってそう。困った。
User.find(1).books # => [<Book id:100>] User.find(1).books << [] # Booking Delete All (xxx ms) DELETE FROM `bookings` WHERE `bookings`.`user_id` = 1 AND `bookings`.`book_id` = 100
この挙動については、rails/rails でも過去に議論になったもののバグではなく仕様であると判断された様子。
解決方法
has many through association に dependent: :destroy オプションを渡せば delete_all ではなく destroy 相当の処理が行われ、after_destroy や after_commit on: :destroy を発火させることができる。
# == Schema Information # # Table name: users # # id :bigint not null, primary key # created_at :datetime not null # updated_at :datetime not null # class User < ApplicationRecord has_many :bookings # ここに `dependent: :destroy` を追加 has_many :books, through: :bookings, dependent: :destroy end
User.find(1).books # => [<Book id:100>] User.find(1).books << [] # Booking Destroy (xxx ms) DELETE FROM `bookings` WHERE `bookings`.`id` = 1
ちなみに has many through association に dependent: :destroy オプションを渡しても多対多の関連先である Book が削除されないことは確認済み。*1
感想
https://github.com/rails/rails/issues/7618 にも書いてあったように、追加時は callback が走って削除時は callback が走らないのは直感的ではないように感じた。且つ、has many through に dependent: :destroy オプションを渡せば destroy callback が発火するのもピンも来ていない。
destroy callback を発火させたくないケースが正直思いつかないので、 has many through を使う時には常にdestroy: :dependent オプションをつけておいてもいいのでは?とさえ思った。
とはいえ、ここを Rails 側が変更するとなるとどうしても破壊的な変更になってしまうので Rails 側の仕様が変わることはなさそう。であれば Cop を作って未然に防ぐなどで自衛するしかないんだろうか...
*1:直感的にはこっちが削除されそうな気がしたので念の為確認した
マイクロサービスアーキテクチャ 第2版では2週間で作り直せるサイズが良いという記述が削除されている
社内でマイクロサービスのサイズについての議論になり、ふと気になってマイクロサービスアーキテクチャ 第2版を確認すると削除されていたことに気付いたよ、というのがこの記事で最も言いたかったことです。*1
以下蛇足です。
マイクロサービスアーキテクチャ 第1版ではマイクロサービスの特徴として、簡単に作り直しができる(2週間で作り直せる程度)ほど十分に小さい点が挙げられていました。*2

マイクロサービスは小さければ小さいほど良いという言説は、マイクロサービスアーキテクチャ 第1版の記述を根拠としていることが多かったように思います。
また、マイクロサービスアーキテクチャ 第1版で挙げられた際に引用していたのは以下のブログだと思います。*3
対して、マイクロサービスアーキテクチャ 第2版ではサイズに関するセクションはあるものの、2週間で作り直せるサイズという記述は削除されていました。代わりに以下のような主張が行われています。
- サイズという概念は最も関心の低い特性の1つ
- 最適なコードベースのサイズはチームや個人など状況に強く依存する
- コードベースのサイズではなく、インターフェースのサイズを小さくすべき
感想
このように第1版と第2版で主張がガラッと変わる書籍はなかなかないのではないでしょうか。 それだけここ数年でマイクロサービスアーキテクチャに関する知見が集まってきたのではないかと思います。
ここ1年くらいでモノリスからマイクロサービスへの書籍がグッと増えたような気がする。先行的に取り組んできた組織がだいたいひと段落して体系的にまとめられる段階に来たということなんだろうか
— てっぺー (@euglena1215) 2023年2月21日

rubocop-ast.wasm を作った
便利そうなツールを作ったという紹介です。
Ruby 30th LT に出したのですが落ちたので供養として書きました。
解決しようと思った課題
Ruby には RuboCop という linter 兼 formatter があります。 RuboCop に元々入っているルール(Cop と呼ばれます)だけでも十分に便利なのですが、自身の Ruby プロジェクトに合わせて独自のルール(Custom Cop)を作ることができます。
Custom Cop の作り方:
- Rubocop でカスタムルールを作る - MoneyForward Developers Blog
- https://sinsoku.hatenablog.com/entry/2018/04/24/02291
- RuboCop の Cop の実装について - Qiita
記事に書かれているように、 ちょっとした実装で Custom Cop が作れるようになっています。しかし、自分を含む普段 Web アプリケーションを作っているエンジニアには親しみの薄い概念が登場します。それは S式(AST)です。*1
RuboCop は対象となるプログラムを parse した AST に対して定義されているルールに一致する AST を見つけ、該当箇所に対して linter として怒るという仕組みになっているので、Custom Cop を作るためには AST を表現する必要があることは理解できます。しかし、難しい…
RuboCop に精通した人であれば以下のようなS式を見て
(send
(send
(const
(cbase) :SomeKlass) :new
(int 1)
(str "foo")
(splat
(send nil :args))) :hoge_method)
「ああ、これはこんなプログラムだな」と理解できるものなのでしょうか。自分には難しすぎる…
::SomeKlass.new(1, "foo", *args).hoge_method
こういった難しさには既視感があるなと思い、思い出したのが正規表現でした。自分も最初は正規表現にとっつきにくさを感じ悪戦苦闘しながら使っていましたが、今ではある程度簡単な正規表現であれば「ああ、こういう文字列とマッチしそうだな」と理解できるようになっています。
なぜそうなったかで思い出すと、体が覚えるまで 正規表現を書いてみる → テスト文字列と一致しているか確かめる → 正規表現を修正する → ... といったトライアンドエラーを繰り返すのが有効だったように思います。
とっつきにくい RuboCop の AST(S式)に対して楽にトライアンドエラーを繰り返せるようになることで、正規表現と同様に「気付いたらなんとなく理解できるようになっている」状態にするにはどうしたらいいか?を考え始めました。
既存の解決方法
既存の方法としては、RuboCop の Cop の実装について - Qiita で紹介されている pocke/rpr が挙げられます。これはプログラムを渡すとS式を返すコマンドラインツールで、以下のような使い方ができます。
% rpr -e "::SomeKlass.new(1, "foo", *args).hoge_method" -p rubocop
s(:send,
s(:send,
s(:const,
s(:cbase), :SomeKlass), :new,
s(:int, 1),
s(:send, nil, :foo),
s(:splat,
s(:send, nil, :args))), :hoge_method)
上級者がパッとS式を確認するのにピッタリなツールのように感じました。しかし、初学者観点だと以下のような特性も持ち合わせているとより使い勝手の良いツールになりそうだと考えました。
- プログラムからS式への変換だけでなく、S式から一致するテストプログラムを確かめられる双方向性
- 入力するたびに変換が行われるようなインタラクティブ性
1,2 の特性を踏まえると、コマンドラインツールよりも Web ツールの方が良さそうです。 そこで、1,2 の特性の持つ Web ツールを作成してみることにしました。 また、個人的なチャレンジとして Ruby 3.2 からの wasm サポートを利用し frontend で完結するスタンドアローンな Web ツールを目指しました。
作ったもの
rubocop-ast.wasm を作成しました。
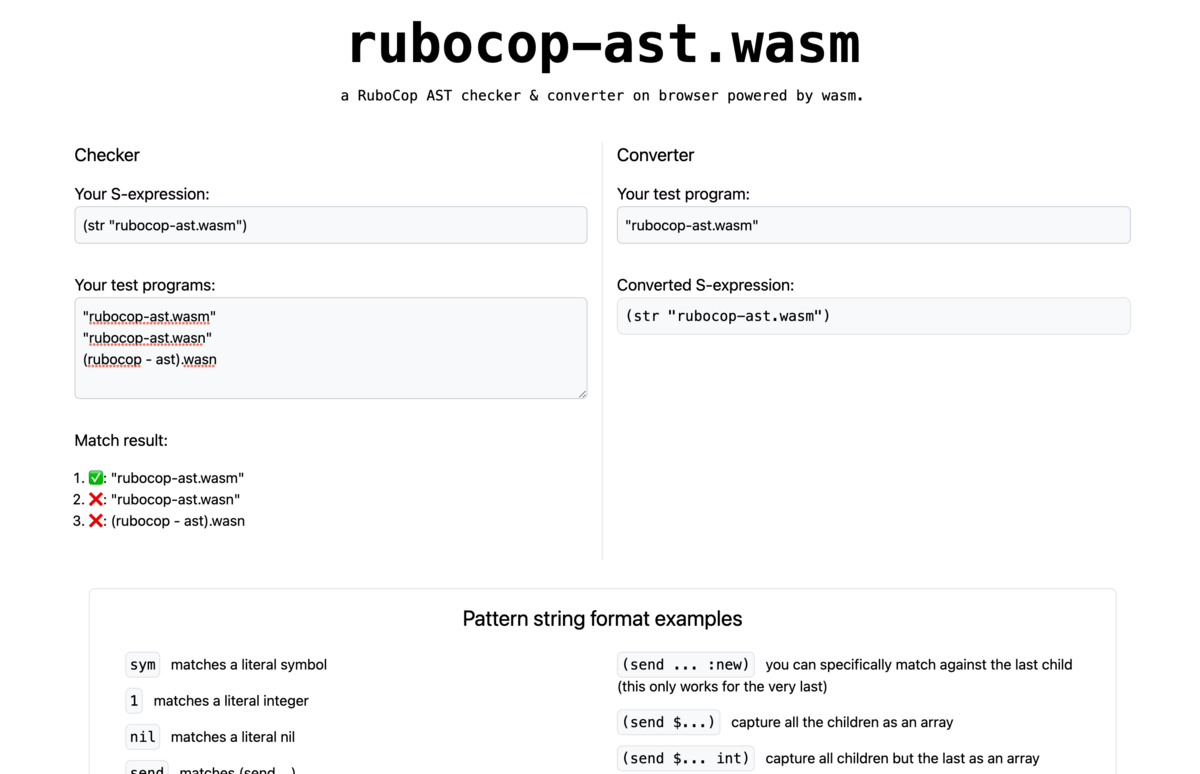
ソースコード: https://github.com/euglena1215/rubocop-ast.wasm
プログラムを渡すとS式に変換する機能とS式とテストプログラムを渡すと一致するテストプログラムを教えてくれる機能を提供しています。どちらの機能も一文字入力を行うごとに変換・検証が行われるので、楽にトライアンドエラーを繰り返すことができます。 このツールを使うことで、S式も正規表現と同様に「気付いたらなんとなく理解できるようになっている」になれると考えています。
ツール名の通り、このツールは wasm を使ってブラウザ上で Ruby を動かしているのでバックエンドの管理が必要ないことも個人開発をする上では嬉しいポイントの1つです。 wasm を使ってブラウザで Ruby を動かす流れについては別途ブログに書く予定です。
(TODO: wasm を使ってブラウザで Ruby を動かす流れについての記事リンクを貼る)
感想
Ruby 3.2 で wasm がサポートされたことにより、ちょっとした CLI の Web ツール化が進むのではないかと感じました。
初学者にとって、コマンドラインツールよりも Web ツールの方が嬉しいことは色々あるんじゃないかと思っています。Web ツール化が進むことで Ruby コミュニティの裾野が広がったらいいですね。
参考にさせていただきました
marginalia(ActiveRecord::QueryLogs) を使うと ActiveRecord::Relation#explain が空文字を返す問題
困っている人向けまとめ
- marginalia(ActiveRecord::QueryLogs) を
prepend_comment = trueの設定で使うとActiveRecord::Relation#explainが空文字を返す問題がある - marginalia に issue が立っていて修正は既に rails/rails に取り込まれている Merge pull request #44350 from fatkodima/explain-prefix-comment · rails/rails@a32c54e · GitHub
- 2022/12/27 時点での最新版の Rails 7.0.4 ではまだ上記の修正が取り込まれていないので同様の monkey patch を当てる必要がある
marginalia を使おうとしたときにちょっと困ったことがあったのでメモ書き。
marginalia とは
marginalia gem とは、rails/rails を作った basecamp が作った gem で SQL のクエリの先頭か末尾にどの controller / action で発行されたかをクエリのコメントとして追記してくれる機能を持っている。
また、この機能は Rails 7 では ActiveRecord::QueryLogs という名前で標準の機能に取り込まれている。便利で使ってたけどメンテされてる気配がなかったので標準に取り込まれるのは嬉しい。
どんな問題が起きたのか
marginalia のデフォルトの挙動では、クエリ発行位置をクエリの末尾にコメントするようになっているが下記のように prepend_comment option を true にするとクエリの先頭にコメントを追記してくれるようになる。
Marginalia::Comment.prepend_comment = true
これを設定した上で ActiveRecord::Relation#explain(e.g. User.all.explain) を実行すると、explain 結果が空文字になってしまう問題が起きていた。
この問題は既知で、ActiveRecord::Relation#explain は with, select, update, delete, insert のいずれかから始まるクエリでないと EXPLAIN が動作しないような実装になっているのが原因とのこと。
どう対応すればいいのか
既に rails/rails に修正は取り込まれているものの、2022/12/27 時点の Rails 最新版である 7.0.4 ではまだ反映されていないので変更に対応する monkey patch をあてる必要がある。具体的には以下。
# config/initializers/marginalia.rb # `Marginalia::Comment.prepend_comment = true` で marginalia を動かすと `ActiveRecord::Relation#explain` が空文字を返す問題の対応。 # 対応自体は https://github.com/rails/rails/commit/a32c54e49e46f08a910a993718bae78e57f3d85f で rails/rails の main branch に取り込まれている。 # 2022/12/27時点でのRails 最新バージョン(7.0.4)には取り込まれていないので、取り込まれたバージョンまで Rails が上げることができればこの monkey patch を消すことができる。 if defined?(ActiveRecord::ExplainSubscriber) && ActiveRecord::ExplainSubscriber.const_defined?(:EXPLAINED_SQLS) ActiveRecord::ExplainSubscriber::EXPLAINED_SQLS = /\A\s*(\/\*.*\*\/)?\s*(with|select|update|delete|insert)\b/i end
新卒で入社した会社を退職しました
この記事は 呉高専 Advent Calendar 2022 - Adventar の21日目の記事です。
新卒で Wantedly という会社に就職し、その会社を今年いっぱいで退職することになりました。 なので、数年後自分がお酒を飲みながらエモい気持ちになるための振り返りとして書き残しておきます。
Wantedly とは
まずは、私が新卒で入社した Wantedly という会社について軽く紹介します。
Wantedly は「シゴトでココロオドルひとをふやす」をミッションに以下のサービスを展開しています。
私が働いていた期間の多くは Wantedly Visit の開発に携わり、最後の2ヶ月ほどは Wantedly Engagement Suite の開発に携わっていました。
Wantedly に新卒で入ってどうだったか?
間違いなく良かったと思っています。
良かったと思うポイントは色々ありますが、以下の2つを取り上げたいと思います。
- 真っ当な toC 向けのプロダクト開発を経験できた
- 色々なことに入門できた
1. 真っ当なtoC向けのプロダクト開発を経験できた
Wantedly では 仮説を立てる → 検証する → 機能としてリリースする → 予想とのギャップを整理する → 予想と機能を修正して再度リリースする → ... という開発サイクルを回していて、 Wantedly のエンジニアはこれらの全工程に関わっています。
これらのサイクル自体はよくあるものだと思いますが、会社によってはエンジニアは機能としてリリースする部分だけを担うこともあると聞いています。 分業による生産性の向上などのメリットもあると思いますが、各ステップを一通り経験できたことは間違いなく自分の経験としてプラスに働いたと考えています。
2. 色々なことに入門できた
前述の 1. 真っ当な toC 向けのプロダクト開発を経験できた でもわかるように Wantedly のエンジニアのカバー範囲はとても広いと感じています。
プロダクトを伸ばすために必要だからやる、という総合格闘技としてのプロダクト開発は自分の性に合っていて、様々な分野で 完全に理解した → 何もわからない → チョットデキル → 完全に理解した → ... を繰り返すことでプロダクト開発力が高まっている実感がありました。
【少し入門した分野】
エンジニアリング、プロダクトマネジメント、プロジェクトマネジメント、グロース、データ分析、UXライティング、...
色々なことに入門したことにより、深淵な「プロダクト開発」というトピックに対して学ぶべきロードマップがうっすら見えたような気がしました。
伸ばしたいスキルの変化
学生の頃から現在までで伸ばしたいスキルが変わっていった*1ことも書いておこうと思います。
学生の頃~社会人1年目
学生の頃は プロダクトを作る能力を高める = 技術力を上げる だと思っていたので、技術力を高められる会社として Wantedly を選びました。*2
入社してからも技術力を高めることが最も重要と考えていたような気がします。
読んでいた本
社会人2~3年目
社会人2~3年目になり、一個人としての成果だけでなく1チームとしての成果を考えるようになりました。
やってきたプロジェクトを見返してみると、プロジェクトの中で設計・実装は一部分でしかなく、もし仮に実装・設計の期間が半分になったとしても、トータルのプロジェクト期間はそこまで短くならないことに気付きました。 さらに、プロジェクトが完遂できたとしてもユーザーのインサイトがズレていて思っていたように数字が伸びないことも多々ありました。
これらの経験から、プロダクトを伸ばすためには技術力を高めるよりもプロジェクトマネジメント・プロダクトマネジメントの能力を磨くことが重要だと考えるようになりました。
読んでいた本
- イシューからはじめよ ― 知的生産の「シンプルな本質」
- プロダクトマネジメント ―ビルドトラップを避け顧客に価値を届ける
- アジャイルサムライ――達人開発者への道
- Hacking Growth グロースハック完全読本
社会人4年目~現在
社会人4年目では、新規事業に近いような事業としての不確実性がとても高いプロジェクトを任されていました。
新規事業のフェーズではどう作るよりも何を作るか、それをどう届けるかの方が圧倒的に重要です。そのため、コンセプトを決める段階からのプロダクトマネジメント、UXライティングなどよりユーザーに近い部分のスキルを高めていました。
そのようなスキルを高めていく中でなんとなく、自分の中のエンジニア濃度が薄まっていくような感覚があり危機感を覚えていました。「技術はあくまで手段」と思っていた自分がなぜ危機感を覚えるのか、プロダクトを伸ばす能力は高まっているんだからそれで十分じゃないか、と思う気持ちと「なんか嫌だな」という気持ちが同時に存在していました。
自分の中で気持ちを整理してみたところ、2つの気持ちがあることに気付きました。*3 どうやらプロダクトを伸ばすだけでは満たされなかったようです。
- プロダクトを伸ばしたい
- エンジニアとしてやっていきたい
そして、エンジニアとしてプロダクトの伸ばす力をより高めるための手段として、転職を決意しました。
(具体的な転職の話は脱線してしまうのでこの記事では書きません)
読んでいた本
新卒の会社を選ぶということ
この記事は呉高専 Advent Calendar として書いたものなので、これから新卒の会社を選ぶであろう学生向けのセクションも書いてみようと思います。
まだ新卒の会社以外をほとんど知らない社会人4年目の言うことなので話半分くらいに読んでください。
パッと思いついたのは以下の3つです。
- 新卒で入った会社の文化や考え方は自分の価値基準に影響する
- 専門性を磨き上げたい!と思っていたとしても新卒で幅広く色んなことができる環境に身を置くのは悪くない
- 一度選んだら正しい選択だったかは考えず、選択を正しくすることに全力を注ぐ
1. 新卒で入った会社の文化や考え方は自分の価値基準に影響する
これはよく言われていることですが、新卒で入った会社の文化や考え方は自分の価値基準に影響する気がしています。
新卒のタイミングでは前職が存在しないため、他社の比較することができません。そのため、まずは良くも悪くもその会社の文化や考え方に染まることになると思います。 2社目以降では前職が存在するため、良くも悪くも「前の会社と比較してここは〜で、あそこは〜」と比較してしまいます。
新卒で選んだ1社目が基準になってくるため、どんな考え方を自分にとっての当たり前にしたいかで会社を選んでみるのも悪くないかもしれません。
2. 専門性を磨き上げたい!と思っていたとしても新卒で幅広く色んなことができる環境に身を置くのは悪くない
これは実体験によるものなので賛否両論あると思いますが、新卒では幅広く色んなことができる環境に身を置くのも悪くないなと感じています。
専門性を磨き上げることが目標であれば何の問題もないと思います。しかし、別の目標があり、その目標を達成するために専門性を磨き上げたいと考えているのであれば、目標を達成する手段は特定の専門性を磨き上げる以外にも存在しないかを確かめる期間があっても良いと思っています。
自分が学生のときは プロダクトを作る能力を高める = 技術力を上げる だと思っていましたが、実務でプロダクト開発を行うことで他にも上げるべきパラメータが存在することを知ることができました。
3. 一度選んだら正しい選択だったかは考えず、選択を正しくすることに全力を注ぐ
これもよく言われていることですが、一度新卒の会社を選んだら正しかったかどうかは考えず、選択を正しくすることに全力を注いだ方がいいと思っています。
これに関しては自分の好きな記事があるのでそちらを参照してみてください。
ActiveModel::Dirty を使うときに気をつけること
最近ハマってしまったのでメモとして残しておく。
TL;DR
自身のmodel と association を同時に save する場合は dirty attribute が上書きされる可能性があるので注意する必要がある。
本編
雑なサンプルを提示する。
- User : ユーザー作成時に新規ユーザー向けのメール送信する機能を持っている
- UserName : User と has_one の関係で UserName 作成時に親の User model の
filled_nameを更新する
# == Schema Information # # Table name: user_names # # id :integer not null, primary key # user_id :integer indexed # name :string(32) # created_at :datetime # updated_at :datetime # class UserName < ApplicationRecord belongs_to :user after_create :mark_as_filled_name private def mark_as_filled_name user.filled_name = true user.save! end end
# == Schema Information # # Table name: users # # id :integer not null, primary key # filled_name :boolean default(FALSE), not null, indexed # created_at :datetime # updated_at :datetime # class User < UsersModel::User has_one :user_name after_save :send_mail_for_new_user private def send_mail_for_new_user MailService.send_new_user_mail(user) if saved_change_to_id? end end
上記のような model が存在したとき、以下のような実装で User と UserName の作成を同時に行うとメールが送信されない。
user = User.new user.user_name.build(name: 'this is name') user.save!
User と UserName の作成を別々に行うときちんとメールは送信される。(同一トランザクションでも問題ない)
user = User.new user.save! user.user_name.create!(name: 'this is name')
どうしてこうなるかを解説していく。
まず、 User と UserName の作成を同時に行う場合の user.save! では以下の処理が順番に実行されている。
- User の create
- UserName の create
- UserName の after_create による User の update
- User の after_save
4. を実行するタイミングでは 1. の dirty attribute(id column の変化) が残っていることを期待するが 3. の User update(filled_name column の変化) によって 1. の dirty attribute が上書きされ、サンプルコードで言うところのsaved_change_to_id?がfalseを返してしまう。
学び
- model の同時 save を行う必要がないときはなるべく別々での save を心がける
- dirty attribute 難しい